Numquam ponenda est pluralitas sine necessitate.
- attributed to
William of Ockham, circa 1300.
Translation:
“Plurality should not be posited without need.”
The above
quotation is understood to be a heuristic principle to aid in the comparison of
different explanations for a set of known facts.
The principle
is often restated as:
‘The simplest
possible explanation is usually the correct explanation.’
This idea is frequently invoked by scientists, engineers, or any other class of person
involved in rational decision making, very often without thinking. We know
instinctively, for example, that when trying to identify the cause of the force
between two parallel current-carrying wires, it is useless to contemplate the
presence of monkeys on the moon. But this is the most trivial form of
application of the Ockham principle, specifying our preferred attitude to
entities of no conceivable relevance to the subject of study.
Less trivial
applications occur when we contemplate things that would have an effect on the
processes we study. In such cases it is still widely and instinctively accepted
that we should postulate only sufficient causal agents to explain the recorded
phenomena. We tend to see the ‘simplicity’ of an explanation, therefore, to be
advantageous. Mathematically, this is related to the complexity of the
mathematical model with which we formulate our description of a process. A linear response model, for example,
when it gives a good fit, is seen as more desirable than a quadratic model. This
may be partly related to the greater ease with which a linear model can be
investigated mathematically, but there is also a feeling that if the fit is
good, then the linear model probably is the true model, even though the
quadratic model will always give a better fit (lower minimized residuals) to
noisy data.
Two problems
arise if we try to make the Ockham principle objective:
(i) How
do we define the ‘simplicity’ of a model?
(ii) How
are we to determine when it is acceptable to reject a model in
favor
of one less simple?
A slightly
loose definition of the simplicity of a model is the ease with which it can be
falsified. That is, if a model makes very precise predictions, then it is
potentially quickly disproved by data, and is considered simple. With a
Bernoulli urn, for example, known to contain balls restricted to only 2
possible colours, the theory that all balls are the same colour is instantly
crushed, if we draw 2 balls of different hues. An alternate model, however,
that the urn contains an equal mixture of balls of both colours is consistent
with a wider set of outcomes – if we draw 10 balls, all of the same colour,
then it is less likely, but still possible that that there are balls of both
colour in the urn.
To make the
definition of simplicity more exact, we can say that the simpler model has a
less dispersed sampling distribution for the possible data sets we might get if
that model is true. P(D | M, I) is more sharply concentrated.
Mathematical
models of varying numbers of degrees of freedom can also succumb to a
characterization of their relative simplicity using this definition. If one
finds that a simple model does not exactly fit the data, then one can usually
quite easily ‘correct’ the model by adding some new free parameter, or ‘fudge
factor.’ Adding an additional parameter gives the model a greater opportunity
to reduce any discrepancies between theory and data, because the sampling
distribution for the data is broader – the additional degree of freedom means
that a greater set of conceivable observations are consistent with the model,
and P(D | M, I) is spread out more thinly. This, however, means that it is harder
to falsify the model, and it is this fact that we need to translate into some
kind of penalty when we calculate the appropriateness of the model.
To see how we
can use Bayes’ theorem to provide an objective Ockham’s razor, I’ll use a
beautiful example given by Jeffreys and Berger1, in ‘Sharpening Ockham’s Razor
on a Bayesian Strop.’ The example concerns the comparison of competing theories of gravity in the
1920s: Einstein’s relativity, which we denote by proposition E, and a fudged
Newtonian theory, N, in which the inverse-square dependence on distance is
allowed instead to become d-(2+ε), where ε is some small fudge
factor. This was a genuine controversy at that time, with some respected theorists refusing to accept relativity.
The evidence
we wish to use to judge these models is the observed anomalous motion of the
orbit of Mercury, seen to differ from ordinary Newtonian mechanics by an
amount, a = 41.6 ± 2.0 seconds of arc per
century. The value, α, calculated for this deviation using E was 42.9’’, a very
satisfying result, but we will use our objective methodology to ascertain
whether in light of this evidence, E is more probably the truth than N, the
fudged Newtonian model. In order to do this we need sampling distributions for
the observed discrepancy, a, for each of the
models.
For E, this is
straightforward (assuming the experimental error magnitude is normally
distributed):
For N, the
probability to observe any particular value, a,
depends not only on the experimental uncertainty, σ, but also on the sampling
distribution for α, the predicted value for the anomalous motion. This is
because α is not fixed, due to the free parameter, ε. We can treat α as a
nuisance parameter for this model:
To find
P(α | N), we note that a priori, there is no
strong reason for the discrepant motion to be in any given direction, so
positive values are as likely as negative ones. Also large values are unlikely,
otherwise they would be manifested in other phenomena. From studies of other
planets, a value for α > 100’’ can be ruled out. Therefore, we employ
another Gaussian distribution, centered at zero and with standard deviation, τ,
equal to 50’’.
P(a | N) can
then be seen to be a Gaussian determined by the convolution of the measurement
uncertainty and the distribution for α:
We’ll consider
ourselves to be otherwise completely ignorant about which theory should be
favored, and assign equal prior probabilities of 0.5.
Bayes’ theorem
in this case is:
and so we get
the posterior probabilities: P(E | a, I) = 0.966 and P(N | a, I) = 0.034, which is nearly 30 times
smaller. Because the fudged Newtonian theory has 2 uncertainties, the
measurement error, and the free parameter, ε, the sampling distribution for the
possible observed discrepancy, a, is spread over a much broader range.
Plotting the
sampling distributions for the observed value, a,
for each of the two models reveals exactly why their posterior probabilities are
so different:
Because E packs so much probability into the region close to the observed anomaly, it
comes out far more highly favored than N. If the actual observation was far from 40’’,
then the additional degree of freedom of model N would be seen to be vindicated.
We can perform
a sensitivity analysis to see whether we would have had a radically different
result upon choosing a slightly different value for τ. Plotted below are the
results for the same probability calculation just performed, but with a large
range of possible values of τ:
The result
shows clearly that we are not doing a great disservice to the data by
arbitrarily setting τ at 50’’. The total absolute variation of P(E | a, I) is less
than 0.04. We can also experiment with the prior probabilities, but remarkably,
the posterior probability for the Einstein theory, P(E | a, I) falls only to 0.76
if P(E | I) is reduced to 0.1. This illustrates the important point that as
long as our priors are somehow reasonably justified, the outcome is very often
not badly affected by the slight arbitrariness with which they are sometimes
defined.
Note that in
order for the posterior probability, P(E | a, I), to be lowered to 0.5, the same
value as the prior, we would need to increase the experimental uncertainty, σ,
to more than 1000’’. This gives some kind of measure of the large penalty paid by
introducing one extra free parameter.
The Ockham
principle is a vague rule of thumb that, as we've just seen, can be derived from a much more
general and quantitative principle, namely Bayes’ theorem. The fact that many
people have been intuitively able to appreciate the validity of Ockham’s razor
for roughly seven centuries is suggestive of how close Bayes’ theorem is to the
way that human brains perform plausible reasoning. And why should it be any
different? Bayes’ theorem is derived from robust logical principles, and it is
no surprise that natural selection might favor information processing
algorithms that mimic those principles.
In its
original informal statement, Ockham’s razor may let us down in some cases,
where there is strong prior information, where the ‘simplicity’ of two models
is difficult to compare using our ill-defined, intuitive understanding of the
term, or where the balance between goodness of fit and the penalty for
complexity is too close for intuition alone to judge. The more general
application of plausible reasoning using Bayes’ theorem, however, provides the
best possible quality of inference, allows all these hard-to-define qualities
(prior belief, simplicity, goodness of fit) to be objectively quantified, and
puts model comparison on a firm logical basis.
[1] W.H. Jeffreys and J.O. Berger, ‘Sharpening Ockham’s Razor on a Bayesian Strop,’ Purdue University technical report #91-44C, August 1991 (
Download here.)

 .
.

 (4)
(4) 


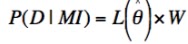

 . We choose the size of V such that the total enclosed
likelihood is the same as the original function:
. We choose the size of V such that the total enclosed
likelihood is the same as the original function:







