In the quantification of uncertainty, there is an important distinction that's often overlooked. This is the distinction between the dispersion of a distribution, and the dispersion of the mean of the distribution.
By 'dispersion of a distribution,' I mean how poorly is the mass of that probability distribution localized in hypothesis space. If half the employees in Company A are aged between 30 and 40, and half the employees in Company B are aged between 25 and 50, then (all else equal) the probability distribution over the age of a randomly sampled employee from Company B has a wider dispersion then the corresponding distribution for Company A.
A common measure of dispersion is the standard deviation, which is the average of the distance between all the parts of the distribution and the mean of that distribution.
Often in science (and in unconscious thought), we will attempt to estimate the mean of some randomly variable parameter (e.g. the age of a company employee) by sampling a subset of the entities to which the parameter applies. This sampling is often done because it is too costly or impossible to measure all such entities. Consequently, it is typically unlikely than an estimate of a parameter's mean (from measurement of a sample) will be exactly the same as the actual mean of the entire population. Thus, out of respect for the limitations of our data, we will (when we are being honest) estimate not only the desired mean, but also the uncertainty associated with that estimate. In doing so, we recognize that the mean we are interested in has a probability distribution over the relevant parameter space.
This is why we have error bars - to quantify the dispersion of the mean of the distribution we are measuring.
Often, however, when estimating the desired error bar (particularly when operating in less formal contexts), it is tempting to fall into the trap of assuming that the distribution over the mean of a variable is the same as the distribution over the variable itself.
These distributions are not the same, and consequently, their dispersions and standard deviations will be different. To see this, consider the following example:
We imagine two experiments consisting of drawing samples from a normal distribution with mean of 0 and standard deviation of 1. In each experiment, the distribution from which we draw is the same, but we draw different numbers of samples. Each experiment is illustrated in the figure below. On the left, the case where 100 simulated samples were produced (using the numpy.random.normal() function, from python), and on the right, the case where 100,000 samples were generated. The samples are histogrammed (with the same binning in each case), and the black line shows the same underlying distribution (scaled by the number of samples).

Because, on the left, we have far fewer measurements to go on, the overall result is affected by much greater sampling error (noise), and the shape of the underlying distribution is far less faithfully reproduced. We can appreciate that the mean obtained from this small sample is likely to be further from the true mean of the underlying process than the mean obtained from the larger sample. Consequently, the error bars for the means should be different, depending on how many samples were collected. The means from these experiments are indicated above each histogram, and indeed, the sample mean on the right is much closer to 0, the mean of the generating distribution, than that on the left, as our reasoning predicts.
For fun (and because an experiment with a respectable random number generator often gives vastly more statistical insight than any amount of algebra), lets continue the analysis further, by repeating our experiments many times, and logging the means of the samples generated in each iteration. Histogramming these means, separately for each sample size, will allow us to visualize the dispersions of the means, and to begin to see how it depends on the number of samples obtained:

(Instead of taking 100,000 samples for the high-n case, I used only 1,000. This was to allow the two resulting histograms to be reasonably well appreciated on the same plot. The histograms are drawn partially transparent - the darkest part is just where the 2 histograms overlap.)
One thing is clear from this result: the dispersion of the mean really is different, when we take a different number of samples. Certainly, regardless if we take 100 samples, or 1,000, the standard deviation of the result is clearly much smaller than the standard deviation of the generating process, which recall was 1 (look at the numbers of the x-axes of the 2 figures). Thus, when looking for an error bar for our estimated population mean, we will quite likely be horribly under-selling our work, if we choose the standard deviation of our sample values.
To serve as a reminder of this, statisticians have a special term for the standard deviation of a parameter upon which the form of some other probability distribution depends: they call it the standard error (a fitting name, since it's exactly what they'ed like to prevent you from making). The most common standard error used is, not surprisingly, the standard error of the mean (SEM). The standard error is a standard deviation, just like any other, and describes a distribution's dispersion in exactly the usual way. But we use the term to remind us that it is not the uncertainty of the entire distribution we are talking about, but the uncertainty of one of its parameters.
A special case
As I've mentioned before, the normal distribution is very important in statistics for both an ontological and an epistemological reason. The ontological reason is from the physics of complicated systems - the more moving parts in your system, the closer its behaviour matches a normal distribution (the central limit theorem). The epistemological reason is that under many conditions, the probability distribution that makes full use of our available information, without including any unjustified assumptions is the normal distribution (the principle of maximum entropy).
Fortunately, the normal distribution has several convenient symmetry properties that make its mathematical analysis less arduous than it might be. So, it'll be both informative and convenient to investigate the standard error of the mean of a sample generated from an independent Gaussian (normally distributed) process, with standard deviation, σ. This standard error will be very straightforward to calculate, and will provide an easy means of characterizing uncertainty (providing an error bar).
Firstly, note that if we add together two independent random variables, the result will be another random variable, whose distribution is the convolution of the distributions for the two variables added.
One of those handy symmetry properties now: the convolution of 2 Gaussians is another Gaussian, with standard deviation given by Pythagoras' theorem:
 Iterating this fact as many times as we need to, we see that the sum of n independent random numbers, each drawn from a Gaussian process with the same standard deviation, σ, has the following standard deviation
Iterating this fact as many times as we need to, we see that the sum of n independent random numbers, each drawn from a Gaussian process with the same standard deviation, σ, has the following standard deviation
This is the result for the sum of the samples. To go from here to the standard deviation for the mean of our samples, we start with a little proof of a more general result for the standard deviation of some parameter, x, multiplied by a constant, a, σax.
Since
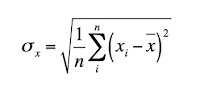 where x̄ is the mean of x, simple substitution yields
where x̄ is the mean of x, simple substitution yields
 Now, the mean of ax is
Now, the mean of ax is
 which is just a times the mean of x, and so
which is just a times the mean of x, and so
 or simply, when a is a constant,
or simply, when a is a constant,



Because, on the left, we have far fewer measurements to go on, the overall result is affected by much greater sampling error (noise), and the shape of the underlying distribution is far less faithfully reproduced. We can appreciate that the mean obtained from this small sample is likely to be further from the true mean of the underlying process than the mean obtained from the larger sample. Consequently, the error bars for the means should be different, depending on how many samples were collected. The means from these experiments are indicated above each histogram, and indeed, the sample mean on the right is much closer to 0, the mean of the generating distribution, than that on the left, as our reasoning predicts.
For fun (and because an experiment with a respectable random number generator often gives vastly more statistical insight than any amount of algebra), lets continue the analysis further, by repeating our experiments many times, and logging the means of the samples generated in each iteration. Histogramming these means, separately for each sample size, will allow us to visualize the dispersions of the means, and to begin to see how it depends on the number of samples obtained:

One thing is clear from this result: the dispersion of the mean really is different, when we take a different number of samples. Certainly, regardless if we take 100 samples, or 1,000, the standard deviation of the result is clearly much smaller than the standard deviation of the generating process, which recall was 1 (look at the numbers of the x-axes of the 2 figures). Thus, when looking for an error bar for our estimated population mean, we will quite likely be horribly under-selling our work, if we choose the standard deviation of our sample values.
To serve as a reminder of this, statisticians have a special term for the standard deviation of a parameter upon which the form of some other probability distribution depends: they call it the standard error (a fitting name, since it's exactly what they'ed like to prevent you from making). The most common standard error used is, not surprisingly, the standard error of the mean (SEM). The standard error is a standard deviation, just like any other, and describes a distribution's dispersion in exactly the usual way. But we use the term to remind us that it is not the uncertainty of the entire distribution we are talking about, but the uncertainty of one of its parameters.
A special case
As I've mentioned before, the normal distribution is very important in statistics for both an ontological and an epistemological reason. The ontological reason is from the physics of complicated systems - the more moving parts in your system, the closer its behaviour matches a normal distribution (the central limit theorem). The epistemological reason is that under many conditions, the probability distribution that makes full use of our available information, without including any unjustified assumptions is the normal distribution (the principle of maximum entropy).
Fortunately, the normal distribution has several convenient symmetry properties that make its mathematical analysis less arduous than it might be. So, it'll be both informative and convenient to investigate the standard error of the mean of a sample generated from an independent Gaussian (normally distributed) process, with standard deviation, σ. This standard error will be very straightforward to calculate, and will provide an easy means of characterizing uncertainty (providing an error bar).
Firstly, note that if we add together two independent random variables, the result will be another random variable, whose distribution is the convolution of the distributions for the two variables added.
One of those handy symmetry properties now: the convolution of 2 Gaussians is another Gaussian, with standard deviation given by Pythagoras' theorem:
|
(1) |
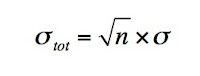
Since
Thus, to go from σtot, the standard deviation of the sum, S, to the standard deviation of the mean, which is S/n, we just divide σtot by n. Applying this to equation (1), we find:
 Simplifying this, we arrive finally at an expression for the standard error of the mean of n samples of a normally distributed variable:
Simplifying this, we arrive finally at an expression for the standard error of the mean of n samples of a normally distributed variable:
And that's it, a cheap and straightforward way to calculate an error bar, applicable to many circumstances.
Note that when x is normally distributed, an error bar given as ± σx̄ corresponds to a 68.3% confidence interval.
A Little Caveat
When the dispersion of the generating process is not initially known we have to estimate σ from the data. If however, the number of samples, n, is fairly small (say, less than 50 or so), the standard formula doesn't work out perfectly. This is because the appropriate prior distribution over σ is not the flat distribution that we tacitly assume when we use
 Instead, we should use the sample standard deviation, s, when calculating the standard error of the mean:
Instead, we should use the sample standard deviation, s, when calculating the standard error of the mean:
|
(2) |

Note that when x is normally distributed, an error bar given as ± σx̄ corresponds to a 68.3% confidence interval.
A Little Caveat
When the dispersion of the generating process is not initially known we have to estimate σ from the data. If however, the number of samples, n, is fairly small (say, less than 50 or so), the standard formula doesn't work out perfectly. This is because the appropriate prior distribution over σ is not the flat distribution that we tacitly assume when we use
In other words, the corrected SEM, accounting for bias in the estimation of σ due to limited sample size, n, will differ from the uncorrected SEM by a simple factor:

(Thus, at n = 50, our standard error will be a tiny bit over 1% too small, if we use the uncorrected version of the standard deviation.)
No comments:
Post a Comment