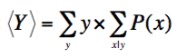Here, I'll give a short summary of one of my favourite studies of recent decades: John Endler's ingenious field and laboratory experiments on small tropical fish1, which in my (distinctly non-expert) opinion constitute one of the most compelling and 'slam-dunk' proofs available of the theory biological evolution by natural selection. After I've done that, in an act of unadulterated vanity, I'll suggest an extension to these experiments that I feel would considerably boost the information content of their results. That will be what I have dubbed 'selection by proxy'.
Don't get me wrong, Endler's experiments are brilliant. I first read about them in Richard Dawkins' delightful book, 'The Greatest Show on Earth,' and they captured my imagination, which is why I'm writing about them now.
Endler worked on guppies, small tropical fish, the males of which are decorated with coloured spots of varying hues and sizes. Different populations of guppies in the wild were found to exhibit different tendencies with regard to these spot patterns. Some populations show predominantly bright colours, while others prefer more subtle pigments. Some have large spots, while other have small ones. Its easy to contemplate the possibility that these differences in appearance are adaptive under different conditions. Two competing factors capable of contributing a great deal to the fitness of a male guppy are (1) ability to avoid getting eaten by predatory fish, and (2) ability to attract female guppies for baby making. Vivid colourful spots might contribute much to (2), but could be a distinct disadvantage where (1) is a major problem, and if coloration is determined by natural selection, then we would expect different degrees of visibility to be manifested in environments with different levels of predation. And so colour differences might be accounted for.
Furthermore, the idea suggests itself to the insightful observer that in the gravel-bottomed streams in which guppies often live, a range of spot sizes that's matched to the predominant particle size of the gravel in the stream bed would help a guppy to avoid being eaten, and that the tendency for particle and spot sizes to match will be greater where predators are more of a menace, and greater crypsis is an advantage.
These considerations lead to several testable predictions concerning the likely outcomes if populations of guppies are transplanted to environments with different degrees of predation and different pebble sizes in their stream beds. These predicted outcomes are extremely unlikely under the hypothesis that natural selection is false. Such transplantations, both into carefully crafted laboratory environments, and into natural streams with no pre-existing guppy populations, constituted the punch line of Endler's experiments, and the observed results matched the predictions extraordinarily closely, after only a few months of naturally selected breeding.
Its the high degree of preparatory groundwork and the many careful controls in these experiments, however, that result in both the high likelihood, P(Dp | H I), for the predicted outcome under natural selection, and the very low likelihood, P(Dp | H' I), under the natural-selection-false hypothesis. These likelihoods, under almost any prior, lead to only one possible logical outcome, when plugged into Bayes' theorem, and make the results conclusive.
The established fact that the patterning of male guppies is genetically controlled served both causes. Of course, natural selection can not act in a constructive way if the selected traits are not passed on to next generation, so the likelihood under H goes up with this knowledge. At the same time, alternate ways to account for any observed evolution of guppy appearance, such as developmental polymorphisms or phenotypic plasticity (such as the colour variability of chameleons, to take an extreme example), are ruled out, hitting P(Dp | H' I) quite hard.
Observations of wild populations had established the types of spot pattern frequent in areas with known levels of predation - there was no need to guess what kind of patterns would be easy and difficult for predators to see, if natural selection is the underlying cause. The expected outcome under this kind of selection could be forecast quite precisely, again enhancing the likelihood function under natural selection.
Selection between genotypes obviously requires the presence of different genotypes to select from, and in the laboratory experiments, this was ensured by several measures leading to broad genetic diversity within the breeding population. This, yet again, increased P(Dp | H I). (Genetic diversity in the wild is often ensured by the tendency for individuals to occasionally get washed downstream to areas with different selective pressures, which is one of the factors that made these fish such a fertile topic for research.)
The experiment employed a 3 × 2 factorial design. Three predation levels (strong, weak, and none) were combined with 2 gravel sizes, giving 6 different types of selection. The production of results appropriate for each of these selection types constitutes a very well defined prediction and would certainly be hard to credit under any alternate hypothesis, and P(Dp | H' I) suffers further at the hands of the expected (and realized) data.
Finally, additional blows were dealt to the likelihood under H', by prudent controls eliminating the possibility of effects due to population density and body size variations under differing predation conditions.
With this clever design and extensive controls, the data that Endler's guppies have yielded offer totally compelling evidence for the role of natural selection. Stronger predation led unmistakably to guppies with less vivid coloration, and greater ability to blend inconspicuously with their environment, after a relatively small number of generations.
I first read about these experiments with great enjoyment, but there was another thing that came to my mind: what the data did not say. It is quite inescapable from the results that natural selection of genetic differences was responsible for observed phenotypic changes arising in populations placed in different environments, but the data say nothing about the mechanism leading to those genetic differences. This, of course, is something that is central to the theory of natural selection. Indeed, we might consider the full name of this theory to be 'biological evolution by natural selection of random genetic mutations.' For the sake of completeness, we would like to have data that speak not only of the natural selection part, but also of the random basis for the genetic transformation.
I'm not saying that there is any serious doubt about this, but neither was there serious doubt about natural selection prior to Endler's result. (In fact, there is some legitimate uncertainty about the relative importance of natural selection v's other processes, such as genetic drift - uncertainty that work of Endler's kind can alleviate.) The theory of biological evolution, though, is a wonderful and extremely important theory. It stands out for a special reason: every other scientific theory we have is ultimately guaranteed to be wrong (though the degree of wrongness is often very small). Evolution by natural selection is the only theory I can think of that in principle could be strictly correct (and with great probability is), and so deserves to have all its major components tested as harshly as we reasonably can. This is how science honours a really great idea.
The established fact that the patterning of male guppies is genetically controlled served both causes. Of course, natural selection can not act in a constructive way if the selected traits are not passed on to next generation, so the likelihood under H goes up with this knowledge. At the same time, alternate ways to account for any observed evolution of guppy appearance, such as developmental polymorphisms or phenotypic plasticity (such as the colour variability of chameleons, to take an extreme example), are ruled out, hitting P(Dp | H' I) quite hard.
Observations of wild populations had established the types of spot pattern frequent in areas with known levels of predation - there was no need to guess what kind of patterns would be easy and difficult for predators to see, if natural selection is the underlying cause. The expected outcome under this kind of selection could be forecast quite precisely, again enhancing the likelihood function under natural selection.
Selection between genotypes obviously requires the presence of different genotypes to select from, and in the laboratory experiments, this was ensured by several measures leading to broad genetic diversity within the breeding population. This, yet again, increased P(Dp | H I). (Genetic diversity in the wild is often ensured by the tendency for individuals to occasionally get washed downstream to areas with different selective pressures, which is one of the factors that made these fish such a fertile topic for research.)
The experiment employed a 3 × 2 factorial design. Three predation levels (strong, weak, and none) were combined with 2 gravel sizes, giving 6 different types of selection. The production of results appropriate for each of these selection types constitutes a very well defined prediction and would certainly be hard to credit under any alternate hypothesis, and P(Dp | H' I) suffers further at the hands of the expected (and realized) data.
Finally, additional blows were dealt to the likelihood under H', by prudent controls eliminating the possibility of effects due to population density and body size variations under differing predation conditions.
With this clever design and extensive controls, the data that Endler's guppies have yielded offer totally compelling evidence for the role of natural selection. Stronger predation led unmistakably to guppies with less vivid coloration, and greater ability to blend inconspicuously with their environment, after a relatively small number of generations.
I first read about these experiments with great enjoyment, but there was another thing that came to my mind: what the data did not say. It is quite inescapable from the results that natural selection of genetic differences was responsible for observed phenotypic changes arising in populations placed in different environments, but the data say nothing about the mechanism leading to those genetic differences. This, of course, is something that is central to the theory of natural selection. Indeed, we might consider the full name of this theory to be 'biological evolution by natural selection of random genetic mutations.' For the sake of completeness, we would like to have data that speak not only of the natural selection part, but also of the random basis for the genetic transformation.
I'm not saying that there is any serious doubt about this, but neither was there serious doubt about natural selection prior to Endler's result. (In fact, there is some legitimate uncertainty about the relative importance of natural selection v's other processes, such as genetic drift - uncertainty that work of Endler's kind can alleviate.) The theory of biological evolution, though, is a wonderful and extremely important theory. It stands out for a special reason: every other scientific theory we have is ultimately guaranteed to be wrong (though the degree of wrongness is often very small). Evolution by natural selection is the only theory I can think of that in principle could be strictly correct (and with great probability is), and so deserves to have all its major components tested as harshly as we reasonably can. This is how science honours a really great idea.
To test the randomness of genetic mutation, we need to consider alternative hypotheses. I can think of only one with non-vanishing plausibility: that at the molecular level, biology is adaptive in some goal-seeking way. That the cellular machinery strives, somehow, to generate mutations that make their future lineages more suitably adapted to their environment. I'll admit the prior probability is quite low, but I (as an amateur in the field) think its not impossible to imagine a world in which this happens, and as the only remotely credible contender, we should perhaps test it.
We could perform such a test by arranging for natural selection by proxy. That is, an experiment much like Endler's, but with a twist: at each generation, the individuals to breed are not the ones that were selected (e.g. by mates or (passively) by predators), but their genetically identical clones. At each generation, pairs of clones are produced, one of which is added to the experimental population, inhabiting the selective environment. The other clone is kept in selection-free surroundings, and is therefore never exposed to any of the influences that might make goal-seeking mutations work. Any goal-seeking mechanism can only plausibly be based on feedback from the environment, so if we eliminate that feedback and observe no difference in the tendency for phenotypes to adapt (compared to a control experiment executed with the original method), then we have the bonus of having verified all the major components of the theory. And if, against all expectation, there turned out to be a significant difference between the direct and proxy experiments, it would be the discovery of the century, which for its own sake might be worth the gamble. Just a thought.
We could perform such a test by arranging for natural selection by proxy. That is, an experiment much like Endler's, but with a twist: at each generation, the individuals to breed are not the ones that were selected (e.g. by mates or (passively) by predators), but their genetically identical clones. At each generation, pairs of clones are produced, one of which is added to the experimental population, inhabiting the selective environment. The other clone is kept in selection-free surroundings, and is therefore never exposed to any of the influences that might make goal-seeking mutations work. Any goal-seeking mechanism can only plausibly be based on feedback from the environment, so if we eliminate that feedback and observe no difference in the tendency for phenotypes to adapt (compared to a control experiment executed with the original method), then we have the bonus of having verified all the major components of the theory. And if, against all expectation, there turned out to be a significant difference between the direct and proxy experiments, it would be the discovery of the century, which for its own sake might be worth the gamble. Just a thought.
| [1] | Natural Selection on Color Patterns in Poecilia reticulata, Endler, J.A., Evolution, 1980, Vol. 34, Pages 76-91 (Downloadable here) |