In recent posts, I've looked at the interpretation of the Shannon entropy, and the justification for the maximum entropy principle in inference under uncertainty. In the latter case, we looked at how mathematical investigation of the entropy function can help with establishing prior probability distributions from first principles.
There are some prior distributions, however, that we know automatically, without having to give the slightest thought to entropy. If the maximum entropy principle is really going to work, the first thing it has got to be able to do is to reproduce those distributions that we can deduce already, using other methods.
There's one case, in particular, that I'm thinking of, and it's the uniform distribution of Laplace's principle of indifference: with n hypotheses and no information to the contrary, each must rationally be assigned the same probability, 1/n. This principle is pretty much self evident. If we really need to check that it's correct, we just need to consider the symmetry of the situation: suppose we have a small cube with sides labelled with the numbers 1 to 6 (a die). Without any stronger information, these numbers really are just arbitrary labels - we could, for example, decide instead to denote the side marked with a 1 by the label "6" and vice versa. But nothing physical about the die will have been changed by this change of convention, so no alteration of the probability assignment concerning the outcome of the usual experiment is called for. Thus each of these two outcomes ("1" or "6") must be equally probable, with further similar arguments applying to all pair of sides.
So if the entropy principle is valid, it must also arrive at this uniform distribution under the circumstances of us being maximally uninformed. Let's check if it works.
We start with a
discrete probability distribution over X, f(x1, x2, …., xn),
equal to (p1, p2, …., pn). The entropy for
this distribution is, as usual given by

which, for reasons
that’ll soon become clear, I’ll express as

Suppose that for f(x1,
x2, …., xn) the probability at x1, p1,
is smaller than p2. Imagine another distribution, f’(X), in which p3
to pn are identical to f(X), but p1 and p2
have been made more similar, by adding a tiny number, ε, to p1 and subtracting
the same number from p2 (this latter subtraction is necessary, so as
not to violate the normalization condition). We want to examine the
entropy of this distribution, relative to the other:

And so the difference
in entropy is:
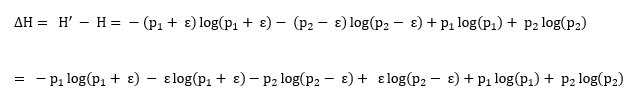
We can consolidate this, using the laws of logs:

In
the 17th century, Nicholas Mercator was a multi-talented Danish
mathematician. His many accomplishments include the design and construction of
chronometers for kings and fountains for palaces, as well as making theoretical
contributions to the field of music. He seems to be the first person to have
made use of the natural base for logarithms, and in 1668 he published a
convenient series expansion of the expression loge(1+x):

We now know this as the
Mercator series. (Remarkably, this work predates by 47 years the introduction of the
Taylor series, of which the above expansion is an example.)
This looks promising to us in the current investigation, as for very small x,
only the first term will remain significant, so we’d like to express the
logarithms in the above entropy difference in this form.
(We might wonder why
this Danish dude had a Latin name, but apparently that was often done in those
days, to enhance one’s academic standing and whatnot – his original name was
Kauffman, by the way, which means the same thing: shopkeeper (I don't understand why he felt it wasn't intellectual enough).
Actually, since moving to the US last year, I see a similar thing going on at
universities here, where it is apparently often considered a highly coveted
marker of status to be able to prove that you know at least three letter of the
Greek alphabet.)
Taking one of those
terms in ΔH, factorizing and again applying the laws of logs:

with a similar result
for log(p2 - ε), so


Supposing we have made ε
arbitrarily small (without actually equaling zero), then when we implement the
Mercator expansion, all terms with ε squared, or raised to higher powers, will
be negligibly small, so
For p2 > p1
and ε > 0, this expression is necessarily positive, meaning that H’ > H,
i.e. the distribution formed by taking 2 unequal probabilities in f, and
adjusting them both to make them more nearly equal results in a new
distribution, f’, with higher entropy.
This procedure of adjusting
unequal probabilities by some tiny ε can, of course, continue for as long as it
takes to end up with all probabilities in the distribution equal, and the
result will necessarily have higher entropy than any of the distributions that
preceded it. This proves that the uniform distribution is globally the one with maximum
entropy.
Another approach we could have taken to check that the entropy principle produces the appropriate uninformative prior elegantly uses the method of Lagrange multipliers, which is a powerful technique employed frequently at the business end of entropy applications. (Yes, that's the same Lagrange, reportedly teased by Laplace in front of Napoleon - but we mustn't think that Lagrange was a fool, he was one of the all-time greats of mathematics and physics, and it probably says more about Laplace that he so easily go the better of Lagrange on that occasion.)
The favorite joke that non-Bayesians use to try to taunt us with is the claim that we pull our priors out of our posteriors. They think our prior distributions are arbitrary and unjustified, and that as a consequence our entire epistemology crumbles. But this only showcases their own ignorance. Never mind the obvious fact that if it were true, no kind of learning whatsoever would ever be possible, for us and them alike. In reality, to derive our priors we make use of simple and obvious symmetry considerations (such as indifference), which not only work just fine, but provide results that stand verified when we apply far more rigorous formalisms, such as maximum entropy and group theory (which I haven't discussed yet).
if you would write a textbook I would buy it in an instance! I'm really enjoying your pedagogical posts on entropy and probability, thanks!
ReplyDeleteI'm sure there are multitudes of people far more qualified to write such text books (and quite a few already have), but thank you very much for the comment. I'm pleased that somebody is enjoying the material!
Delete